
Scraping historical merchant review data from Google
- Preamble
- The Challenge
- The Automation
- The Long Wait
- Analysis & Outcome
- Is it worth it?
- Is there a better way?
- Reference
Preamble
Recently, I was tasked to scrap historical google review data for my current employer. I came across 2 types of Google reviews, Google Location Review and Google Shopping, a.k.a merchant review. There is an API available to scrape the location reviews, but not for the latter. I was tasked with fetching the merchent review. The only way forward was to do the good old scraping.
The Challenge
Google does not make it very easy to scrape merchant reviews. Say you want to look at the merchent review Data for catch.com.au, you need to visit this url. Google loads 10 reviews in one shot, and clicking Show more reviews at the bottom of the page would load 10 more reviews under the same DOM element. This means dealing with an ever-growing list of DOM elements. And that is the crux of the problem.
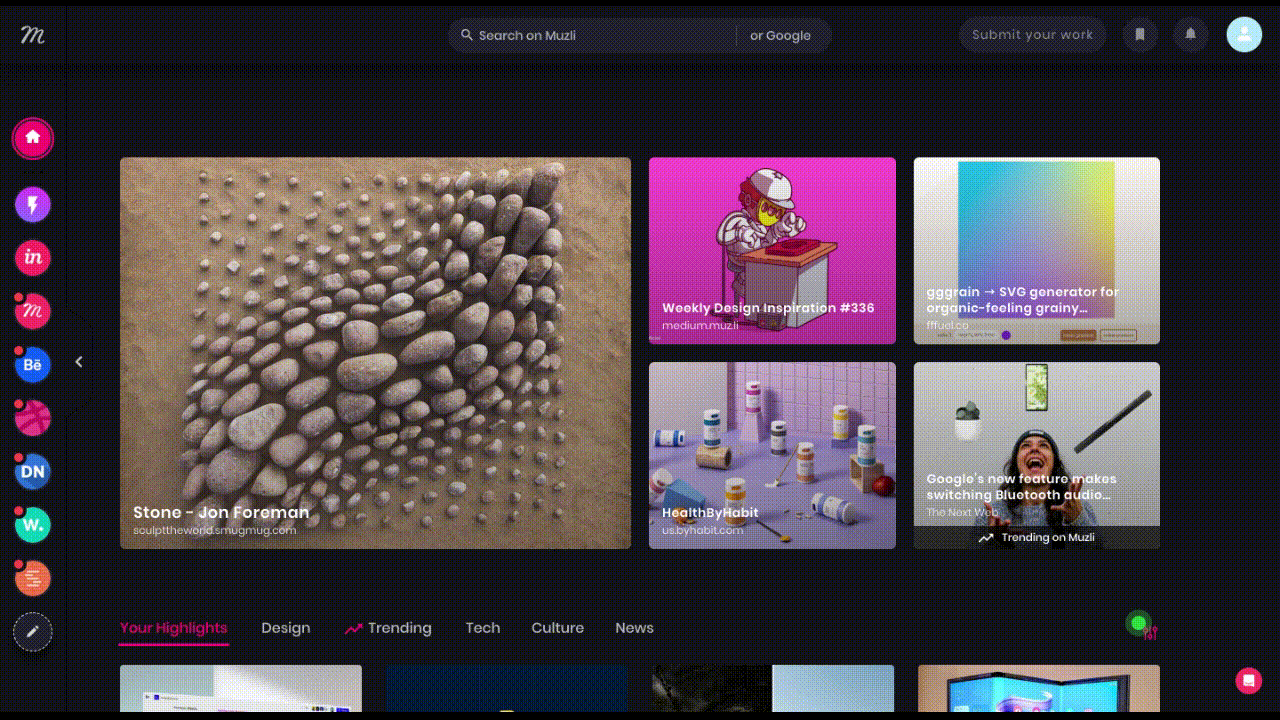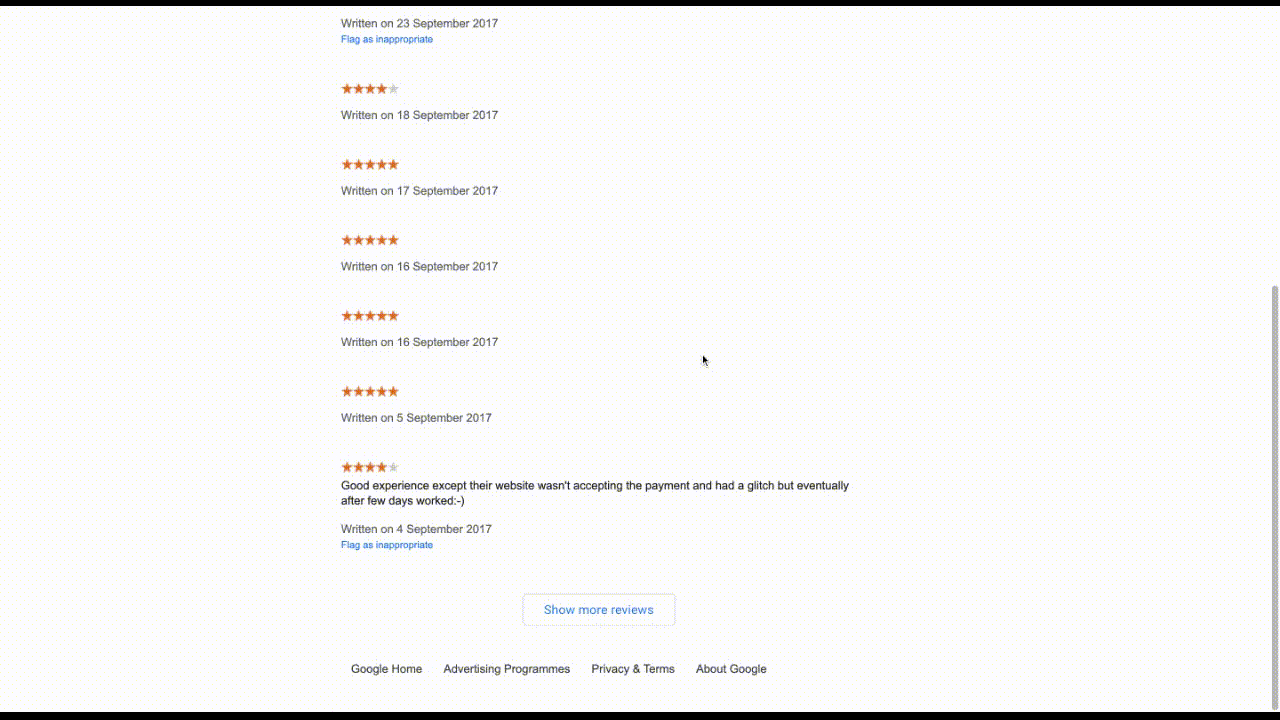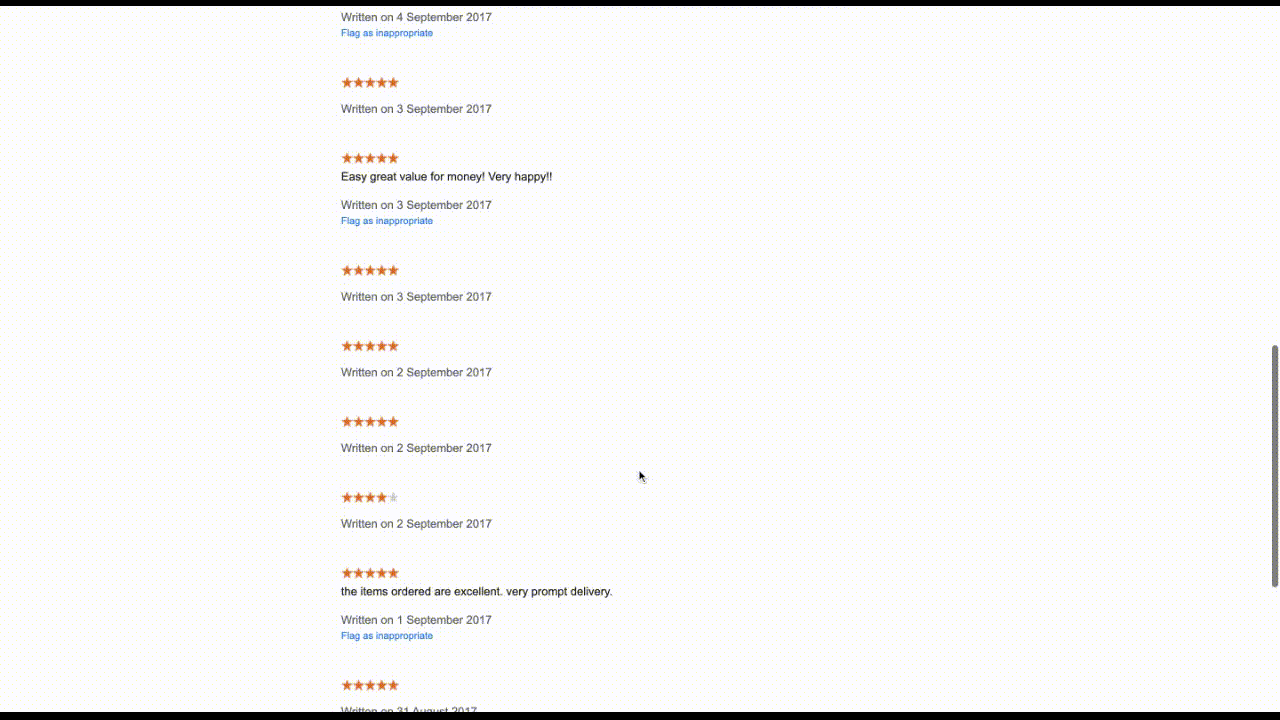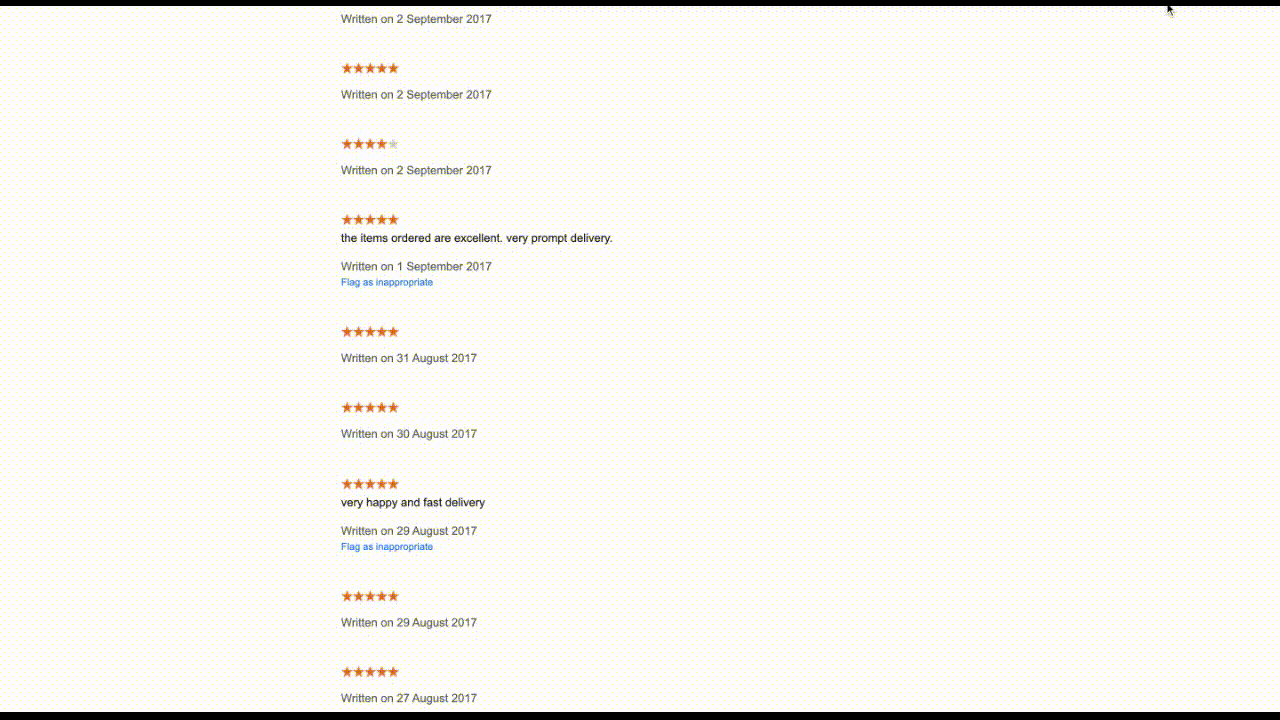
The Automation
The automation basically codifies the above process of keeping clicking Show more reviews. Here is the code:
- import and selenium setup:
import sys
sys.path.insert(0,'/usr/bin/chromedriver')
from selenium import webdriver
import time, os, psutil, random
from selenium.webdriver.common.keys import Keys
import pandas as pd
from datetime import datetime
process = psutil.Process(os.getpid())
chrome_options = webdriver.ChromeOptions()
chrome_options.add_argument('--headless')
chrome_options.add_argument('--no-sandbox')
chrome_options.add_argument('--disable-dev-shm-usage')
driver = webdriver.Chrome('chromedriver', options=chrome_options)- Initial setup, the month and year is just the upper bound; all reviews before this month are to be discarded.
name='catch.com.au'
url = f'https://www.google.com/shopping/customerreviews/merchantreviews?q={name}'
probability = 0.1
month = 'August'
year = 2018
out_file = 'review_2018.csv'
driver.get(url)
all_match_found = False
previous = list()- Helper funcions to extract review data from DOM elements.
def filter_elements(element):
if len(previous) == 0:
return True
if element in previous:
return False
return True
def extract_review_for_month_year(revs, month:str, year:int):
# extract review data
global all_match_found
month_index = months.index(month)
for rev in revs:
review_date = rev.find_element_by_class_name("CfOeR").text
if (month in review_date or any(n in review_date for n in months[month_index:12])) and (str(year) in review_date):
if random.random() < probability:
print(f'{datetime.now().strftime("%d/%m/%Y %H:%M:%S")}::date in process: {review_date}')
score.append(rev.find_element_by_class_name("ujLN8e").get_attribute("style"))
date.append(rev.find_element_by_class_name("CfOeR").text)
text.append(rev.find_element_by_css_selector("div:nth-of-type(2)").text)
elif str(year - 1) in review_date:
all_match_found = True
print(f'{datetime.now().strftime("%d/%m/%Y %H:%M:%S")}::We crossed our review month, nothing else to look for here!!')
else:
#all_match_found = True
if random.random() < probability:
#all_match_found = True
print(f'{datetime.now().strftime("%d/%m/%Y %H:%M:%S")}::date in process: {review_date}, is before our start date!!!')- Extract review data as list of DOM elements and process.
previous_count = 0
while not all_match_found:
time.sleep(3)
driver.find_element_by_class_name("VfPpkd-vQzf8d").click()
current = driver.find_elements_by_class_name("SzAWKe")
if len(current) - previous_count < 10:
print(f'{datetime.now().strftime("%d/%m/%Y %H:%M:%S")}:: >>>>>> It only fetched {len(current) - previous_count} elements!!! Probably it did not load 10 reviews!!!! There will be duplicate data!!')
previous_count = len(current)
to_process = current[-10:]
if len(list(filter(filter_elements, to_process))) == 0:
print('{datetime.now().strftime("%d/%m/%Y %H:%M:%S")} >>>>>>>>!!!! ALERT !!!!either there are no more reviews to process, or selenium could not load any more reviews!!')
break
if random.random() < probability:
print(f'{datetime.now().strftime("%d/%m/%Y %H:%M:%S")}::Reviews scanned so far: {len(current)} && review to be processed {len(to_process)}')
print(f'{datetime.now().strftime("%d/%m/%Y %H:%M:%S")}:: memory used in MB : {process.memory_info().rss/1048576}')
extract_review_for_month_year(to_process, month, year)
previous = to_process
print(f'{datetime.now().strftime("%d/%m/%Y %H:%M:%S")}::Processing done. Total reviews processed: {previous_count}')- Dump the reviews in a file
df=pd.DataFrame()
score, text, date = [], [], []
months = ['December', 'November', 'October', 'September', 'August', 'July', 'June', 'May', 'April', 'March', 'February', 'January']
text = ['' if i[:11]=='Written on ' else i for i in text]
df['score'], df['text'], df['date'] = score, text, date
df.score = df.score.astype(str).str.replace('width: ', '').str.replace('%;','').astype(int)
df.date = pd.to_datetime(df.date.astype(str).str.replace('Written on ', ''))
df.to_csv('reviews_2021.csv')
df.head()The Long Wait
It is essential to clarify that this post is not about how to scrape the reviews. That is trivial in some sense. The above code is not optimal either. Selenium may not be the best tool for this, but that is beside the point. This post is about the aftereffect of taking this route.
It took almost 2 months to run this script. I did a quick and dirty analysis of the log file generated by the above code; you may find it here.
Analysis & Outcome
This experiment extracted 1642 reviews and rejected 5461 reviews. The rejection is that the reviews were written before August 2018. We reached this filter on 28 September 2021, around 25 days after starting the experiment. Rephrasing this, we took 25 days to process the first 5461 reviews, followed by 32 days to process 1642 reviews. This is evident from the below graph.

This can be attributed to Google’s merchant review page design. As I have mentioned before, the reviews load in chronological order on the same page, under the same root DOM element. This means managing an always growing list of DOM elements throughout the process. All along this experiment, my fear was that the program would crash due to a lack of memory. So I chose to run the script on a 4 vCPU 16GB box in GCP, fully expecting it to crash midway (I did not imagine it taking 2 months). To my utter surprise, based on random sampling, most of this resource remained unused throughout this experiment; CPU and memory usage never crossed 30%. Selenium is written in Java; thus, the default JVM parameters are the culprit. It was too late when I realized it thought.

So, the above graph is misleading, a missed opportunity. The above graph only shows the python script’s memory usage, which does not say much. I suspect I could have fast-tracked this whole process by tweaking the JVM parameters for Selenium.
Is it worth it?
It’s hard to say; the business eventually got what it was after. This was definitely not the optimal thought.
Is there a better way?
If any of the readers manage to extract a better outcome either by tweaking the JVM parameters or using a better tool, please let me know.
Reference

I'm a father, husband, life long learner, maker / hacker, avid reader, traveller, photographer and foodie in this exact order of priority.